

一、配置要求
- 操作系统:Windows 10/11 | macOS 12+ | Linux (Ubuntu 20.04+)
- Python 3.8+
- CUDA 11.8+ (如需GPU加速)
- 存储空间:至少10GB可用空间
- 内存:推荐16GB+
二、依赖安装
1、CUDA 和 cuDNN 安装与配置
首先在cmd中输入 nvidia-smi ,右上角表示支持的最高版本的CUDA版本。
如果低于11,请更新显卡驱动程序。
随后前往CUDA官网下载CUDA工具:
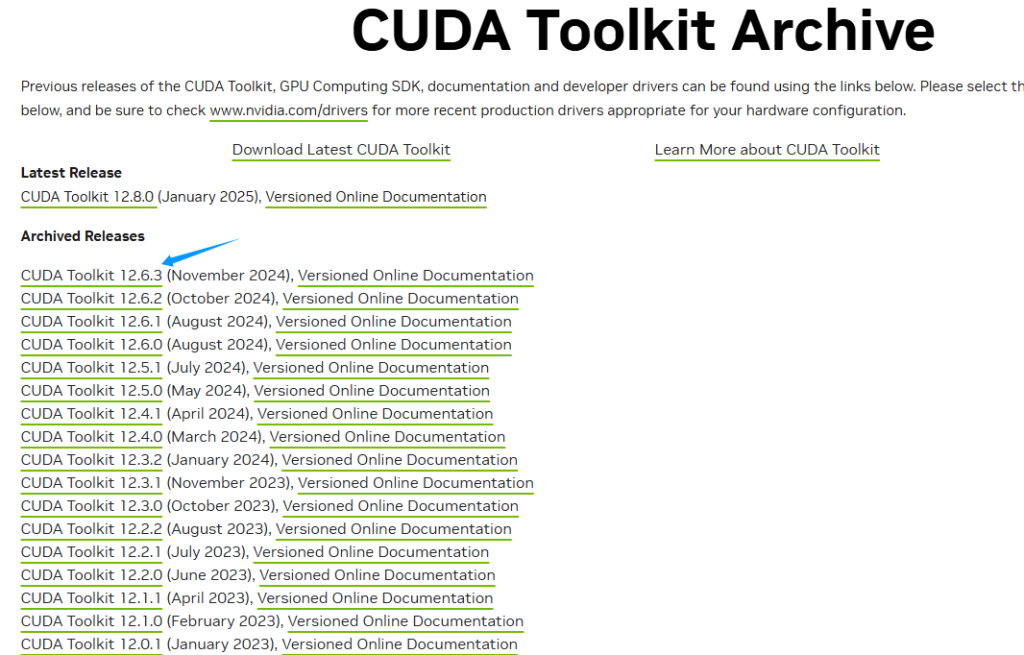
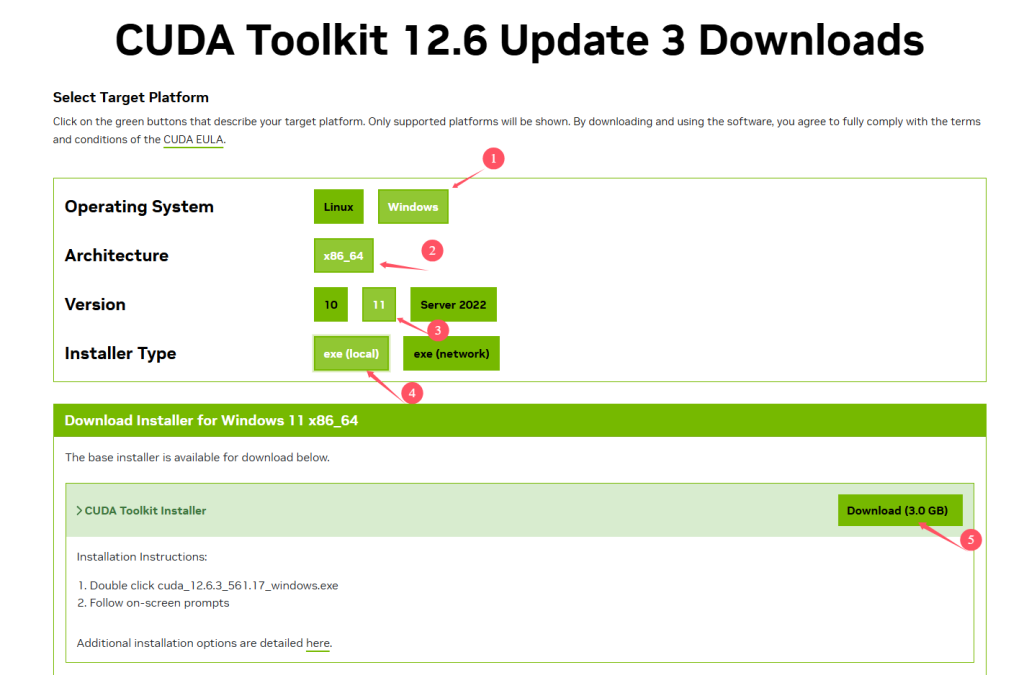
随后运行安装程序即可,务必记住CUDA的安装路径,随后要用。
接着下载cuDNN:
前往cuDNN下载页面,注册NVIDIA账户,下载与你CUDA版本匹配的cuDNN
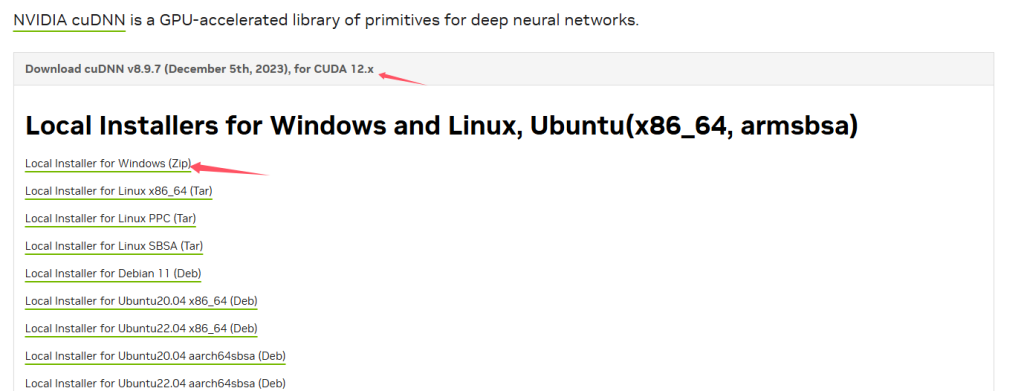
下载完成后解压下载的cuDNN压缩包,将里面的bin、include、lib文件夹复制到你的CUDA安装目录中。
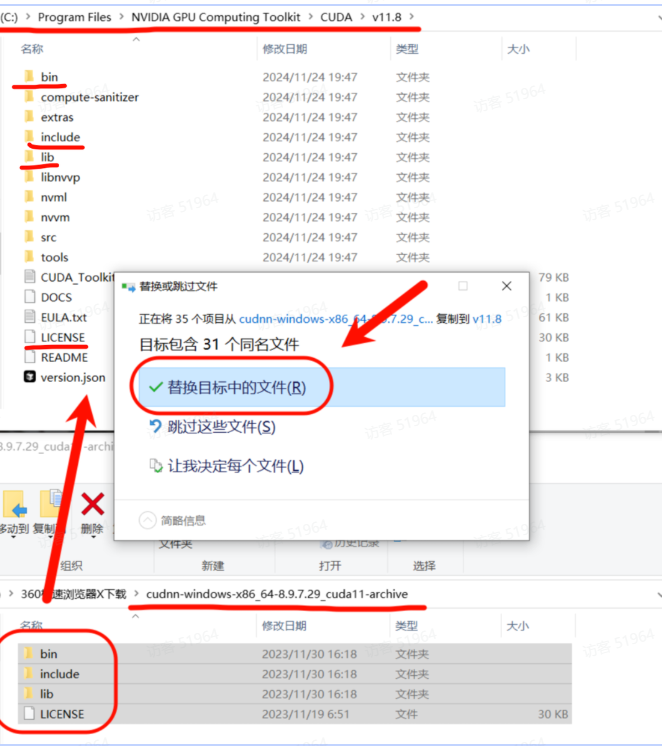
需要新建 4个环境变量,分别是:
CUDA 版本根目录: C:\Program Files|NVIDIA GPU Computing Toolkit)CUDA|v11.8
版本下的 bin 目录: C:(Program Files\NVIDIA GPU Computing Toolkit)CUDAlv11.8)bin
版本下的 include 目录: C:\Program Files\NVIDIA GPU Computing Toolkit)CUDA|v11.8\include
版本下 lib 下的 x64 目录: C:\Program Files\NVIDIA GPU Computing Toolkit)CUDA|v11.8\lib)x64
在新建一个系统变量,变量名CUDNN,值为四个路径中间用";"分隔,如:C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.8;C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.8\bin;C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.8\include;C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.8\lib\x64
2、Git 安装与配置
前往Git官方下载地址下载安装即可,过程很简单,不做赘述。
3、Anaconda 安装
详情请看我之前的文章:Anaconda安装指南
4、克隆 CosyVoice 项目
首先新建一个存放此项目的目录如D:\CosyVoice
随后在这个目录中右键,在终端中打开,输入:
git clone --recursive https://github.com/FunAudioLLM/CosyVoice.git
cd CosyVoice
git submodule update --init --recursive5、依赖项安装
打开Anaconda Prompt,输入
conda create -n cosyvoice python=3.12
conda activate cosyvoice
//如果报错init问题:
conda init cmd.exe以上代码创建了一个虚拟环境,随后安装依赖项:
在目录文件中找到requirements.txt文件,修改其中的
onnxruntime-gpu==1.18.0; sys_platform == 'linux
onnxruntime==1.18.0; sys_platform == 'darwin' or sys_platform == 'windows'将其变更为:
onnxruntime-gpu==1.18.0然后,安装cython和pynini:
先安装 Cython :
pip install cython -i https://pypi.tuna.tsinghua.edu.cn/simple再安装 pynini :
conda install -y -c conda-forge pynini==2.1.5最后,安装 requirements.txt 的依赖项:
pip install -r requirements.txt如果下载的慢,你可以使用这两个镜像源:
//指令1:使用阿里云镜像:
pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/ -trusted-host=mirrors.aliyun.com
//指令2:使用清华镜像:
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple最后验证pytorch是否安装成功:
python -c "import torch; print(torch.__version__)"6、下载预训练模型
新建python文件,命名为,输入:
from modelscope import snapshot_download
snapshot_download('iic/CosyVoice-300M', local_dir='pretrained_models/CosyVoice-300M')
snapshot_download('iic/CosyVoice-300M-SFT', local_dir='pretrained_models/CosyVoice-300M-SFT')
snapshot_download('iic/CosyVoice-300M-Instruct', local_dir='pretrained_models/CosyVoice-300M-Instruct')
snapshot_download('iic/CosyVoice-ttsfrd', local_dir='pretrained_models/CosyVoice-ttsfrd')执行安装:
conda activate cosyvoice
pip install --upgrade modelscope
python download_models.py三、启动CosyVoice
CosyVoice目前有 3 种模型,分别是:
1.内置音色模型
2.克隆音色+跨语种克隆模型
3.内置音色+语气微调模型
运行的 2 种方案:
1.命令行直接运行:
这个方案,就是在 cmd 中直接运行指令,内置音色模型
conda activate cosyvoice
python webui.py --port 50000 --model_dir pretrained_models/CosyVoice-300M-sFT
start http://127.0.0.1:50000b.克隆音色+跨语种克隆模型
conda activate cosyvoice
python webui.py --port 50001 --model_dir pretrained_models/CosyVoice-300M
start http://127.0.0.1:50001\c.内置音色+语气微调模型
conda activate cosyvoice
python webui.py --port 50002 --model_dir pretrained_models/CosyVoice-300M-Instruct
start http://127.0.0.1:50002四、整合包直接部署
如果你认为这些操作太麻烦了,可以看看B站up主Love丶伊卡洛斯做的整合包:

【TTS】CosyVoice1+2 Win整合包,内置FastAPI Gradio WebUI,内置300M,0.5B模型【开源项目】
Comments NOTHING